Neural Network (신경망)
신경세포 = Neuron
이 뉴런을 이용해 layer 만든 것을 우리는 Perceptron 이라고 부른다.
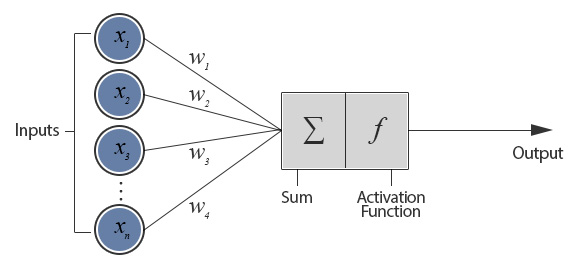
퍼셉트론
자 그럼
각각 weight 들이 있고 이게 vector로 나타날거고
이것들을 합하고. bias더하고.
이렇게 입력과 가중치가 곱해져서 나온 것에 activation function을 적용시킨다.
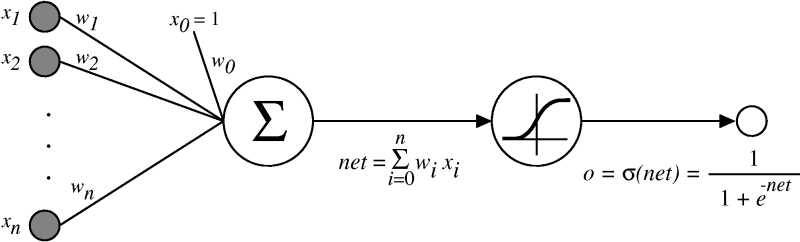
sigmoid 를 자주 쓰는데, 시그모이드 함수를 이용하면
back propagation에서 학습계산처리가 쉬워지므로 역전파 이용할때 전달함수로 자주 사용한다.
예를 들어 하나의 신경망에 두개의 입력(x1, x2) = (0,0) 입력이 들어왔다고 가정해보자.
그리고 w1=1, w2=1, bias값은 -1.5, activation은 계단함수를 이용한다.
그럼 1*0+1*0-1.5 = f(-1.5)이므로 게단함수적용하면 0 이다. (음수는 모두 0처리)
반대로 bias를 조정해서 1로 만들 수 도 있다.
이런식으로 신경망은 bias와 activation function을 변경하면 달라진다.
어떤행동을 하도록 하려면 그 행동에 해당하는 bias와 activation function 을 결정해야 한다.
자 그럼
레이어를 여러개 만들수도 있다. 여러개의 인공신경을 조합하여 신경망을 구성한다면.
이것들을 층층이 쌓아 어떤층의 출력과 다음층의 입력을 계속 잇는것이다.
위에 perceptron들을 죽 이어서.. 싱글레이어 만들고
그 싱글레이어가 여러개 겹겹이 있는 형태이다.
자 이렇게 앞에서부터 feed forward 형 네트워크를 구성한다.
그럼 MultiLayer를 구성하는 네트워크에서. Backpropagation은 어떻게 이루어지는가!!!
input layer, hidden layer(중간층들), output layer로 구성되는 계층적인 신경망이다.
input layter는 입력신호를 다음 hidden에 전달하기만 하는 고정화된 레이어이다.
hidden은 가중치와 bias를 무작위로 초기화한 레이어이다.
이에 비해 output은 학습과정에 따라 변경할 수 있다.
- 출력을 해보고, 출력값이 원래 나와야 하는 데이터보다 작다면 출력이 커지도록 앞단의 layer의 w, bias를 바꿈
- 언래보다 크게나왔다면 출력이 작아지도록 변경.
예를 들어 오차 = 실제label 답 - 학습에의한 값
이렇게 오차를 점차 줄여가는 방법으로..
Loss function은 최종적으로 하나이다. 마지막에
Deep learning
원리적으로 신경망은 어떤 데이터를 이용해도 학습이 거의, 가능하다.
최근 GPGPU연산에 따라 신경망 학습 성능도 향상되어 뜨고있다.
GPU를 병렬계산장치로 이용하는 (General purpose computring on GPU)
그런데 계층이 복잡해질수록, 역전파를 이용한 오차 전달이 잘 되지 않는다.
출력에서 ㅇ입력을 향해 오차를 전파하는 과정에서 가중치나 전달함수의 미분값을 곱해나가다보면..
오차값이 작아져 학습이 진행되지 않는 문제가 있다.
특히 시그모이드 함수를 activation=전달함수 로 쓰면 미분계수가 항상 1 미만이 되므로 다층일때 오차값을 점점 작에 만드는 더 큰 문제가 있다.
1) Vanishing gradient problem
- 중간에 그라디언트가 사라진다. function자체에 문제가 있을수도 있고..
2) Overfitting
3) training 시간
암튼 그래도, 이런 문제를 해결하기 위해 다양한 방법이 제안되었다.
CNN (convolution neural network) 도 그 중 하나이다.
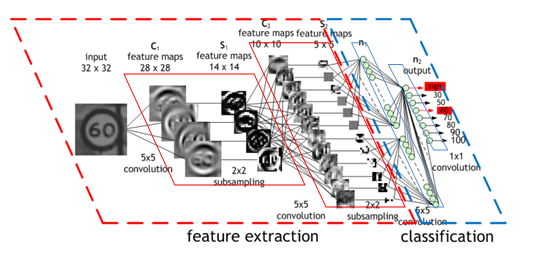
합성곱 신경망(CNN)에서는 기존 신경망의 구조를 바꾸어 학습의 어려움을 해소하였다. 특히 이미지 인식분야의 딥러닝으로 잘 성능을 보인다고 알려져있다.
이것의 기본은, 문제에 특화된 망 구성을 하여, 다층구조의 망을 간소화하여 망학습을 쉽게 하는 것이다.
보통
입력 -> CNN -> POOLING -> CNN -> POOLING ... FUlly connected layer -> 출력이다.
기존 신경망 구조가 모두 fully conneted layer라고 했을 떄 이것은 다르다
CNN, Pooling 이라는 층이 있고
층들끼리 모두 다 결합하는게 아니라, 어느 특정 인공신경끼리만 결합한다. 또 각각 층마다 처리 방식이 다르다.
Convolution Layer의 특징은?
입력신호에 포함된 특징을 추출하는 것이다. 예를 들어 입력신호가 2차원 이미지라면 합성곱층에서는 세로방향,가로방향의 도형성분을 추춣거나 이미지가 가진 특정 픽셀을 추출한다.
즉 이미지 필터. 역할을 한다.
CNN에서는 이미지 필터의 기능을 신경망의 학습기능을 이용하여 자동으로 얻는다.
아래 그림과 같이, 전단계의 대응하는 부분과만 결합하여 어떤일부분의 특징을 추출한다.
Pooling Layer의 특징은?
입력신호를 흐리게 하여 정보 위치의 뒤틀림에 대한 대처를 강하게 한다.
즉 전단계의 좁은영역중의 평균값 or 최대값을 가져온다.
나는 이 그림이 젤 이해하기 쉬웠다

Weight을 잘 할당하는 방법
1) Minibatch SGD
- 랜덤샘플로 모델을 업데이트하고, minibatch를 통해 다양한 랜덤샘플을 접해서 문제를 완화시킨다.
매번 weight을 업데이트하는게 아니다.
2) Momentum
- 이전 방향을 기억하고, history를 가지고 update한다
3) Weight Decay
- 정교한 weight을 넣겟다는 목적으로, weight자체 업데이트를 좀 죽인다.

'IT > Deep learning' 카테고리의 다른 글
| Moving average and Moving variance (0) | 2021.03.18 |
|---|---|
| DL - RCNN, Fast RCNN, FCN, DeconvolutionNetwork (0) | 2017.06.30 |
| DL - Convolutional Neural Network (0) | 2017.06.29 |
| DL - Deep Neural Network (0) | 2017.06.29 |
| Test22222 (0) | 2014.04.16 |