<Introduction>
Lookahead Optimizer 는 기존 optimizer를 사용하여 k 번 gradient descent 수행 후, 첫 번째 theta 방향으로 돌아가는 방법을 반복한다. loop에서 한 단계 다시 back하여 gradient descent를 다시 수행함. 주로 로컬 미니마를 벗어나기 어려울 때 좋은 성능을 보여준다고 함
<Method>
Optimizer는 Adam 또는 SGD와 같은 것들을 써서 두 세트(이중루프)의 theta를 반복적으로 업데이트함. 가중치는 k step마다 천천히 업데이트 됨. 이때 방향 자체는 바깥 루프 기반으로 이루어짐. 두 loop의 가중치는 soft update. 즉 부 분 비율이 적용되어 동기화됨. alpha값은 하이퍼파라미터임. 이렇게 하면 로컬 미니마 피하고 학습 안정성을 개선, 내부 최적화의 분산을 낮춰준다 함. 알고리즘 step은 아래와 같음
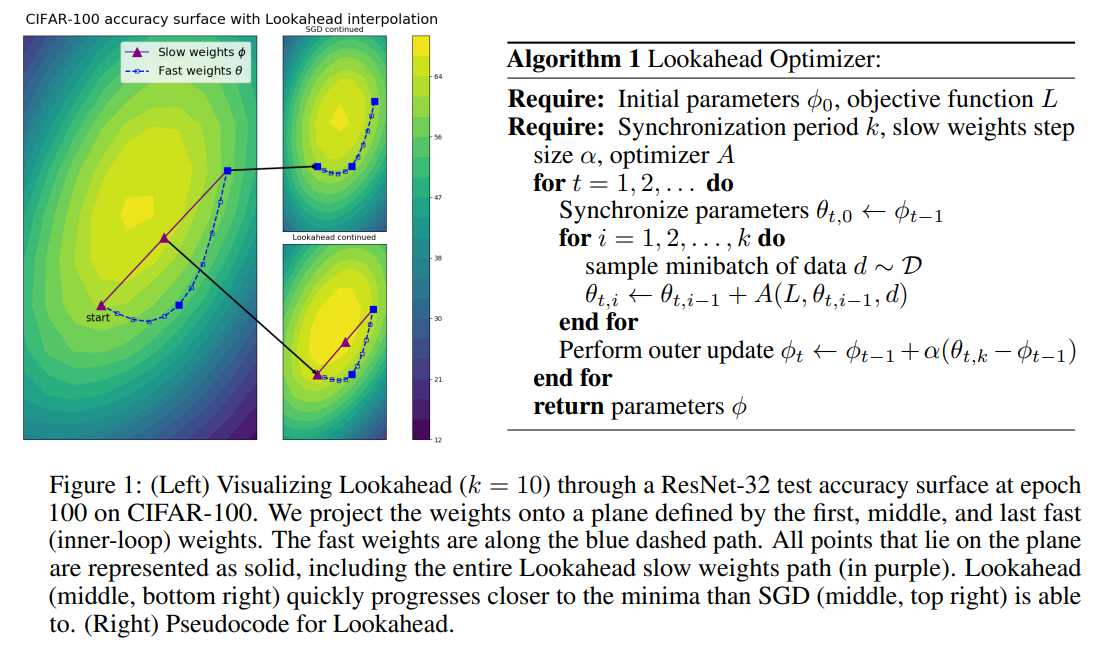
출처
papers.nips.cc/paper/2019/file/90fd4f88f588ae64038134f1eeaa023f-Paper.pdf