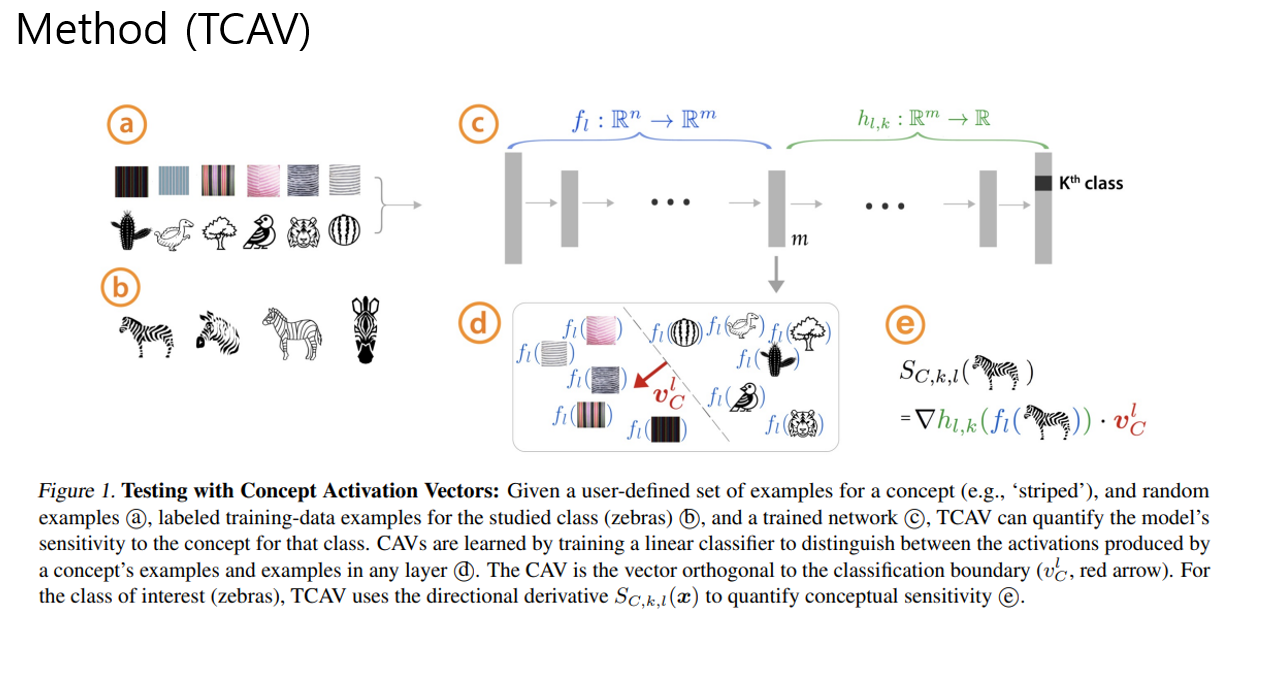
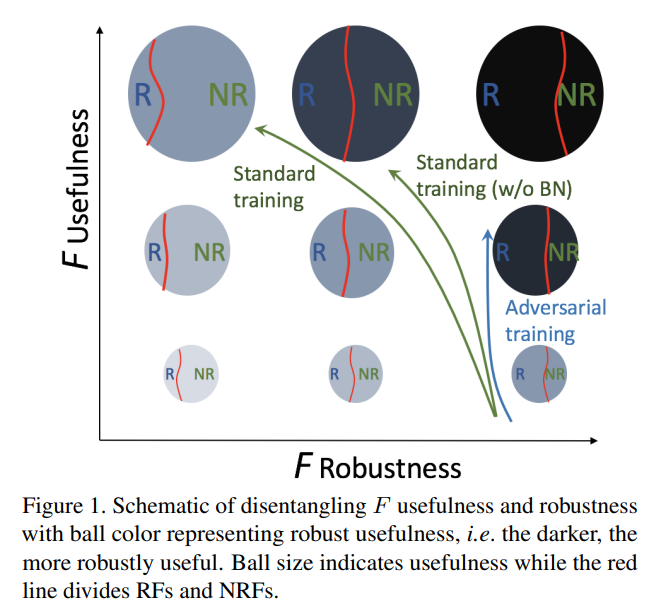
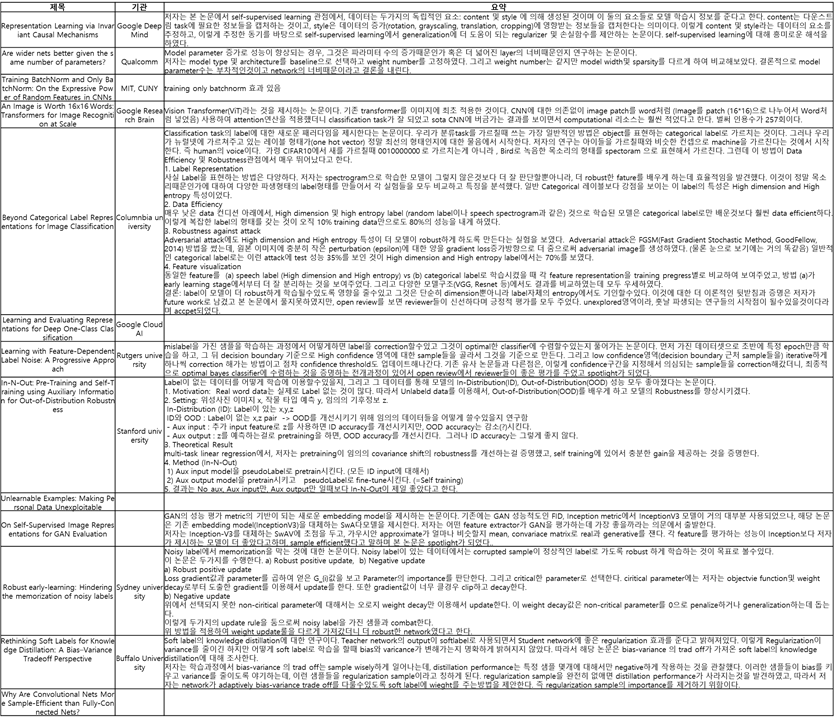
ICML 2017 논문 (https://arxiv.org/abs/1703.01365) Attribution이란 모델의 input과 output간의 관계를 파악하는 것을 의미하는데, 본 논문에서는 Attribution에 대한 주요성질을 정의하고 그것을 충족시키는 intergrated gradient라는 방법을 제안한다. 두 조건은 1) sensitivity baseline과 input과 차이나는 feature가 non-zero attribution값을 가지는 경우 sentivity 조건을 만족함 gradient로는 특정지점에서 0이 될수있기때문에 이 조건이 충족되지 않을수도있음. 2) implementation invariance 서로 다른 network구조이지만 같은 input -> output 관계를 ..