Adversarial Examples Are Not Bugs, They Are Features 논문 (NeurIPS 2019) 을 읽고 discussion 6가지 정도가 distill에 소개되었음. 하나씩 포스팅해보기로 함
Learning from Incorrectly Labeled Data
Ilyas et al. 연구[1]의 section 3.2 에서는 adversarial example에 대해서 모델을 훈련하더라도 모델이 일반화를 잘함을 보여주었고 이것은 데이터의 non-robust를 보고 배웠기 때문이다. 라고 말하면서 non robust도 충분히 일반화에 도움이 된다. 라고 말한다.
그러나 본 discussion에서는 이러한 실험이 error로부터 모델이 학습하는 특정 사례라고 반박하고 있음
먼저 완전히 잘못 레이블링된 training set을 x는 변경시키지 않고 y만 바꿔서 모델을 학습시킨다. (사실 직관적으로는 이러한 데이터셋으로 학습된 모델은 레이블이 올바른 original test set에 대해서는 일반화되서는 안될것임)
그럼에도 불구하고 우리는 이러한 직관이 실패됨을 보여줌
먼저 2 epoch정도 CIFAR10으로 ResNet18 을 학습시킴 -> 이 모델은 train/test acc 각 62.5/63.1 정도 나옴.
다음 50000개 학습 셋을 모델에 넣어 각 예측값을 얻는다. 여기서 제대로 예측된 데이터셋은 제거시키고 잘못 예측된 18,768개를 그 레이블 그대로(잘못예측된값) 으로 다시 새로운 ResNet18을 초기화 후 50 epoch 학습시킴

위 셋팅같은 이상한 경우에도 Test 결과가 50% 정도는 acc가 나와주었다. 라는 실험이다. 여기서 쓰인 데이터셋은 완전히 잘못된 레이블만으로 구성되어있으나 여전히 50%는 일반화 될 수 있었다.
어떻게 위 모델과 Ilyas et al. 의 모델이 잘못된 레이블로도 일반화할 수 있었을까? 여기서 우리는 훈련된 모델을 사용하여 얻은 레이블이기때문에, 해당 훈련 모델에 대한 정보가 mislabeled example로 leakage (유출)되고 있었다고 볼 수 있다. 특히 이것은 model distillation의 간접적인 형태 [2] 라고 함. (위 같은 종류의 dataset으로 학습하면 새 모델이 어느정도는 원래 모델의 본 기능을 recover 할수있음)
Two-dimensional Illustration of Model Distillation
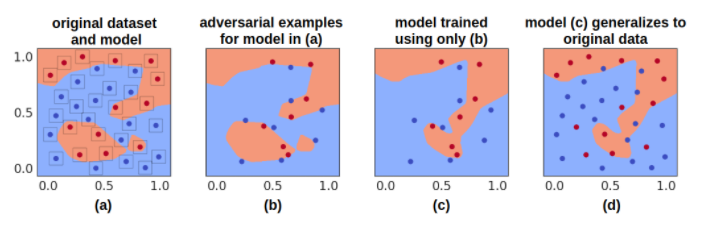
(a) 2차원 bindary문제로 심플하게 adversarial example을 구성해본다. 먼저 32개의 데이터 포인트 생성하고 레이블을 임의로 할당한다. 다음 작은 model로 학습해서 32개를 올바르게 예측한다.
다음은 각 데이터포인트에 대해 L_ ball만큼 epsilon 0.12정도의 adversarial example을 만든다. (그림 (a) 데이터 포인트 근처 사각형 보면 L ball 확인가능)
(b) 위 셋팅으로 모델 예측을 변경시켜주는 adversarial example을 생성하였다.
(c) 위 데이터들로 다시 새로운 모델을 훈련시킨다.
(d) 위 잘못된 데이터(b)를 이용했으므로 올바른 레이블을 본적은 없으나 original 데이터에서 23/32 만큼은 제대로 맞춘다고 함. decision boundary도 러프하게 일치한다고 함. 이 2차원 셋팅은 잘못된 label을 사용하여서도 distillation을 수행할 수 있다는 흥미로운 결과를 보여줌 (2차원 셋팅이니까 non robust / robust 하고 말게 없음)
Other Peculiar Forms of Distillation

위 실험들은 mislabel된 example을 사용해도 모델을 만들 수 있음을 보여줌. 그럼 더 이상한 방법(e.g., out of domain data)으로도 모델을 배울 수 있을까 확인해보기로함.
먼저 MNIST에서 간단한 CNN모델을 훈련해서 99.1% acc를 얻음. 그리고 Fashion-MNIST를 이 모델로 돌려서 각각에 대한 예측 레이블을 얻음. (예를 들면 신발이 2로 레이블링 되고 하는)
다음 새로운 CNN모델을 위 F-MNIST와 위에서 얻은 레이블로 모델을 학습함. 그리고 MNIST로 다시 테스트 해보니 91.04% acc 얻음. 만약 MNIST mean/variance 로 F-MNIST 정규화하면 모델은 94.5%까지 올라감
즉 새로운 모델이 잘못된 레이블로만 훈련했음에도 불구하고, 기능적으로 유사한 모델을 original과 같이 만들어내는 흥미로운 실험임.
-> 위 결과는 레이블이 잘못된 adversarial example로만 사용해서 모델을 훈련하고 예측하는것이 예측 오류로부터 학습하는 특별한 케이스임을 보여줌.
즉 Ilyas et al. 연구의 section 3.2 에서 perturbation을 추가한 adversarial example로 relabeling해서 학습를 하는데, 모델이 이러한 mislabel 데이터에도 generalization을 잘하는 결과를 보이는 것에 대해, "모델이 non-robust feature를 보고 배웠어. non robust feature만으로도 일반화성능을 잘 낼수있어!" 라고 말하는 실험이 있다. 그러나 사실은 perturb 없었어도 학습은 가능했을 것이다. 로 위 discussion을 요약할 수 있다.
[1] Adversarial Examples Are Not Bugs, They Are Features, Ilyas et al. NeurIPS 2019, https://arxiv.org/abs/1905.02175
[2] Distilling the Knowledge in a Neural Network, G. Hinton et al, 2015, https://arxiv.org/abs/1503.02531