성별, 인종, 특정 패턴(줄무늬)같은 내가 생각한 컨셉이 실제 모델 예측에 있어서 얼마나 sensitivity를 주었는지 확인해볼수있는 방법으로, 검증하고자 하는 컨셉 C를 고르고 random data를 골라서 classifier를 학습시킨 후 -> 해당 classifier의 orthogonal vector를 CAV (weight vector) 라고 정의함.
CAV를 이용해서 원본 image에서 컨셉벡터단위로 움직여보고 해당 특정 클래스에 대한 sensitivity값이 특정 값 이상으로 나오는지를 통해 모델 해석 설명하는 논문임
아래 내용은
https://beenkim.github.io/slides/TCAV_ICML_pdf.pdf 및 논문에서 가져와 재구성하여 만든 발표 자료로 컨텐츠 모두 beenkim에서 온것임


기존 sailency map기반 xai방법으로는 해당 이미지가 인출기라는것에 대해 이미지의 어떤 컨셉이 중요하게 작용한건지를 알기 힘들었다. 예를 들면 사람이 인출기앞에 잇는것도 중요하게 작용하는지 등, 또한 다른 cash machine 이미지들도 비슷한 이유로 그렇게 맞추는지 등을 알기가 어려움
따라서 user가 선택한 컨셉이 얼마나 중요하게 양적으로 작용하는지에 대해 알면 좋지 않을까라는 니즈에서 시작되어 해당방법론을 제안함

Human friendly한 컨셉의 관점에서 신경망 내부 상태를 해석하는 활성화 벡터 CAV를 제안함.
핵심아이디어는 신경망 고차원 internal state를 활용, 사용자가 정의한 개념이 분류결과에 중요한 정도를 정량화 하기 위해 방향 도함수를 사용하는 CAV 개념을 제안 -> CAV 활용하는 TCAV를 소개함

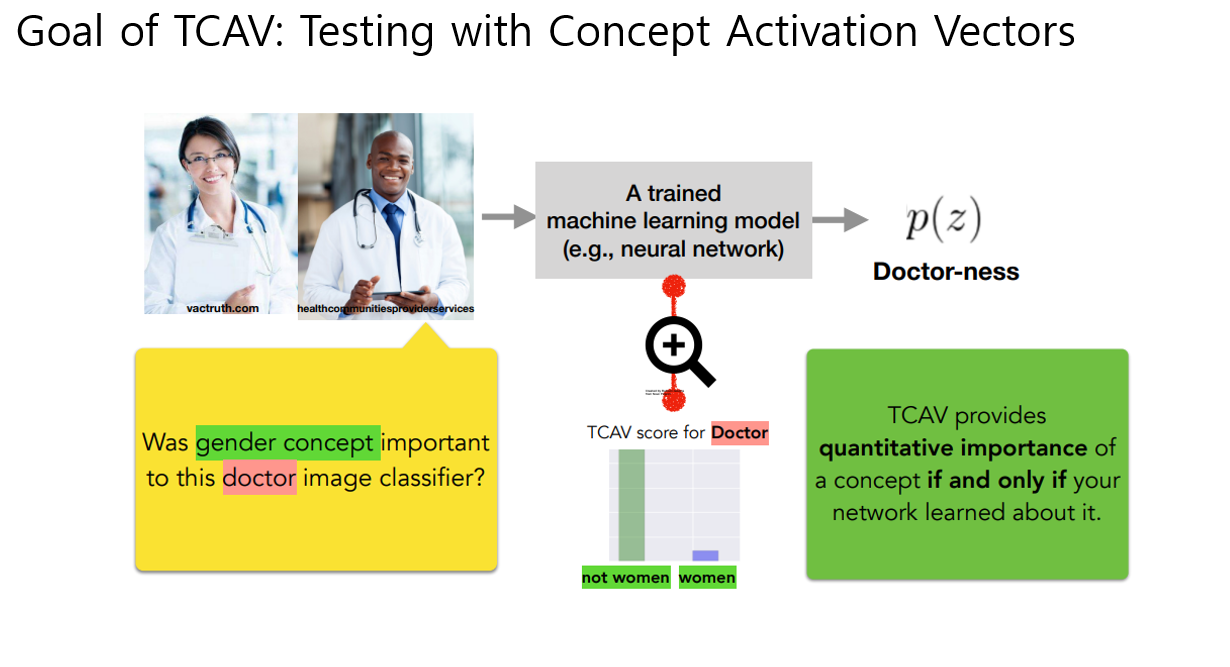
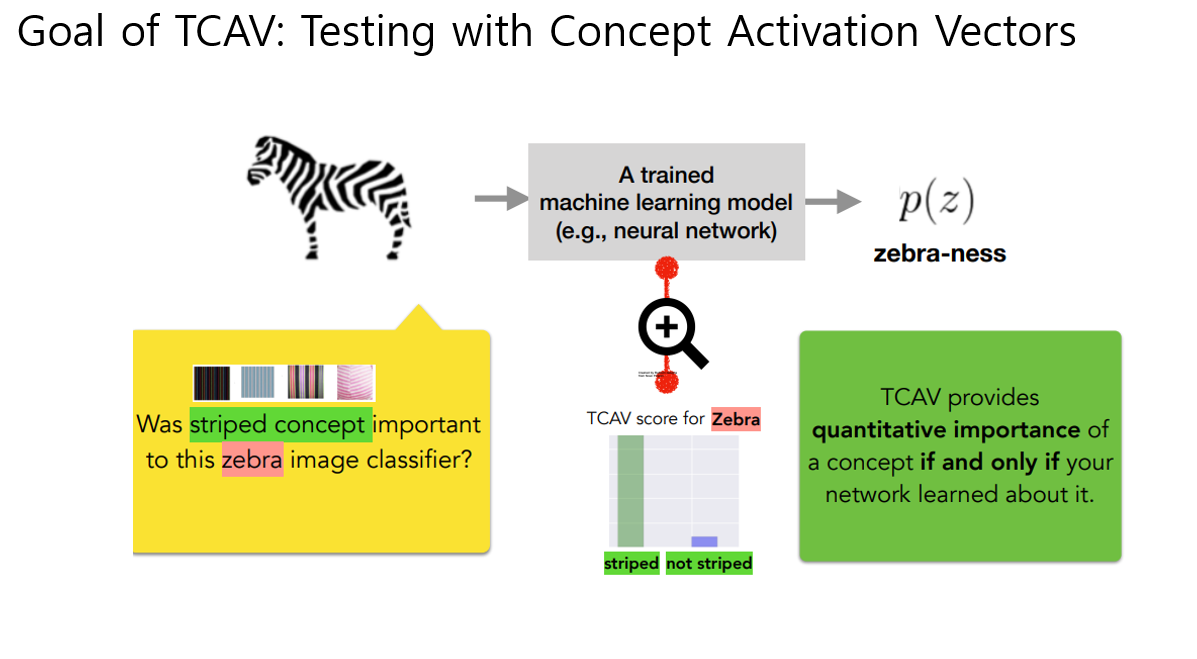
이전에 나온 예시처럼 우리모델이 얼룩말에 줄무늬컨셉이 미치는 sensitivity알고싶다. 하면
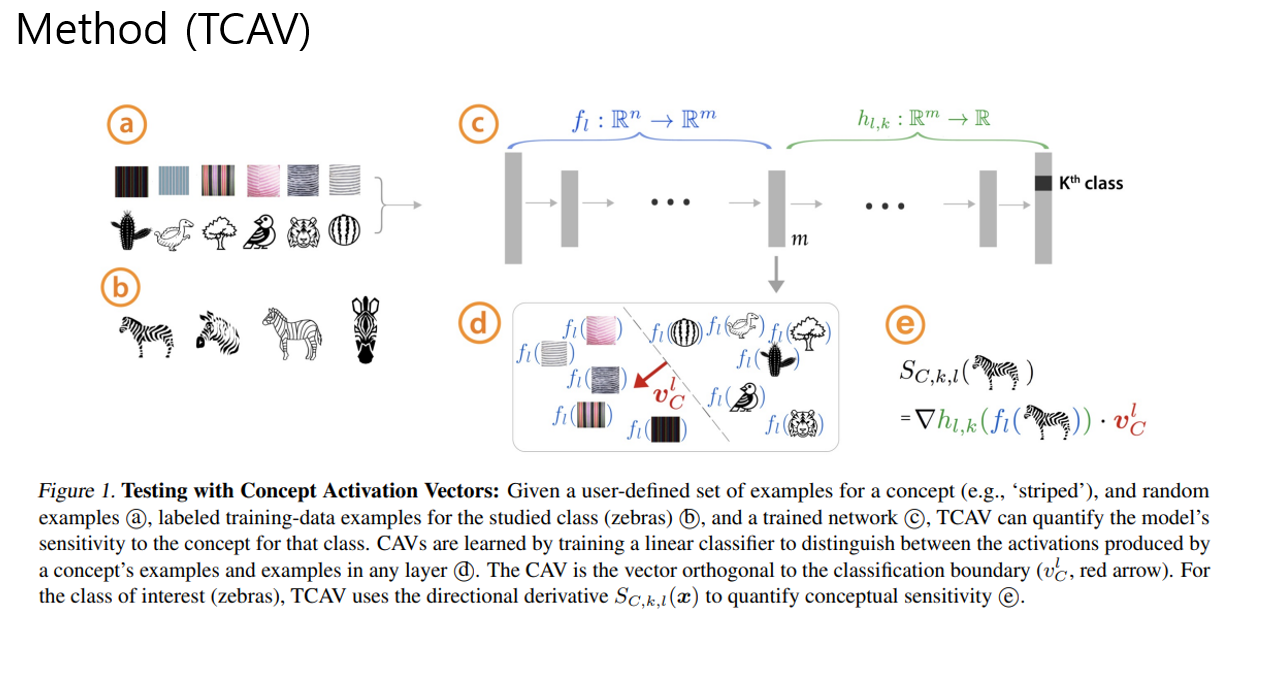
먼저 CAV를 정의해야함. 우리가 학습시킨 모델의 특정 layer l에서 사용자가 관심잇는 컨셉에 대한 activiation값들로 학습을 시킴 -> 줄무늬 이미지만 모으고, 그 외에 랜덤이미지를 모아서 binary classifier를 학습시킴 (구글이미지검색같은데에서 10~20장 정도 뽑아서 학습햇다고함) 그럼 decivison boundary의 orthogonal vector 가 stripeness를 학습한 vector가 될텐데 이걸 CAV라고 부름

이 CAV가 얼룩말에 미치는 sensitivty를 보기위해, strip CAV가 변했을때 얼룩말의 logit값에 대한 모델 민감도는 위와 같은 미분으로 구할수있고, 이걸 conceptual sensitivty라고 부른다. 그리고 얼룩말 sensitivty가 양수인 갯수의 비율을 TCAV라고 부름

1) cosine similarity 확인
CAV가 정말 해당 컨셉을 반영하고 있는지 확인하기 위한 실험임
interest picture set에서 각각 CAV와의 cosine similarity를 계산. (CAV 학습시키는데 포함되지 않은 이미지로)
CEO concept을 배우고, 줄무늬 이미지들을 넣었는데, 넥타이에서 온듯한 stripe가 제일 유사하게 나왔다고 함
Women concept을 배우고, 넥타이 이미지들을 넣었는데 여자컨셉이 더 많이 나왔다고 함
이것을 통해 CAV가 정말 해당 컨셉을 잘 배웟다고 말함
2) 딥드림
실제로 학습된 CAV를 시각화 했더니, 해당 컨셉의 semantic한 개념과 일치하더라. 이 결과를 통해 TCAV가 특정 layer에서 학습되는 direction이나 패턴을 정의하고 시각화할수있음을 이야기함
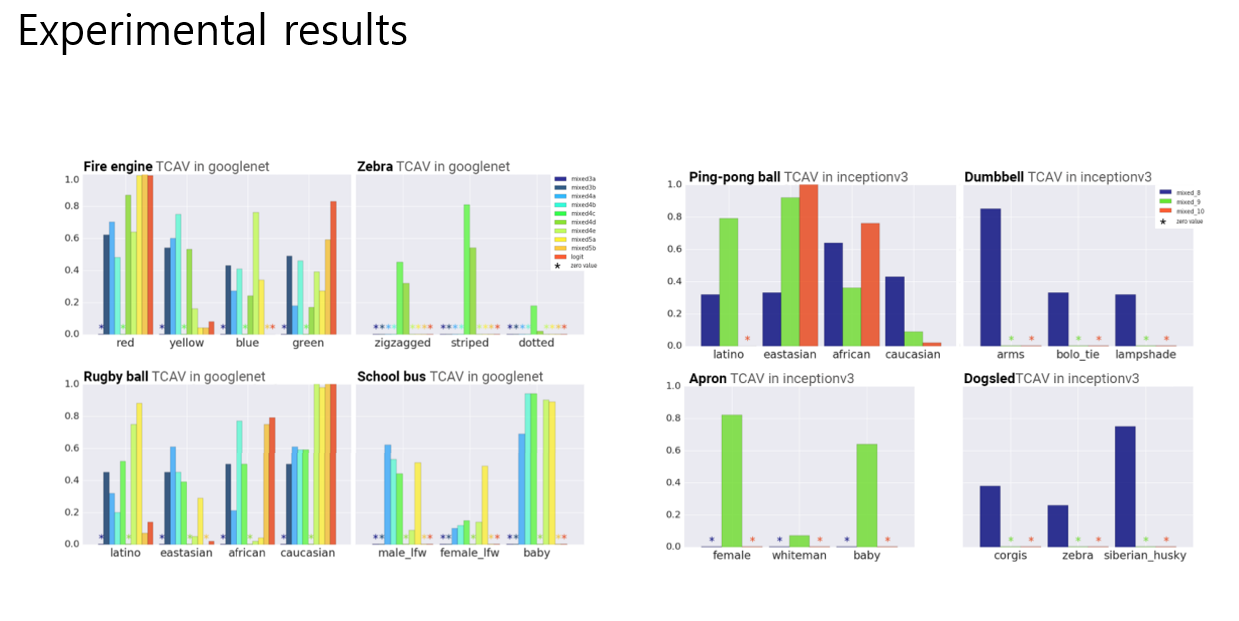
인사이트 검증. 구글넷, 인센션 V3
tCAV를 두개의 네트어크에 적용: TCAV유용성 검증, bisae확인, 어떤컨셉이 배워졌는지
Red concept: 소방차, 줄무늬 지브라, 시베리안컨셉: 개썰매
결과를 통해 모델이 이러한 컨셉으로 명시적으로 훈련되지 않았음에도 불구하고 성별과 인종에 민감하다는 우리의 의심을 확인시켰다고 함
예를 들어, TCAV는 발견된 탁구공이 특정 인종과 높은 상관관계가 있다는 정량적 확인을 제공
인종컨셉은 마지막 layer 에서 더 강한 signal을 보이고 반면, texure컨셉은 더 앞 레이어에서 경향을 보임
덤벨 class는 arm이 아주 큰 영향을 보였다. 30개의 이미지로만 CAV를 배워도 충분했다.
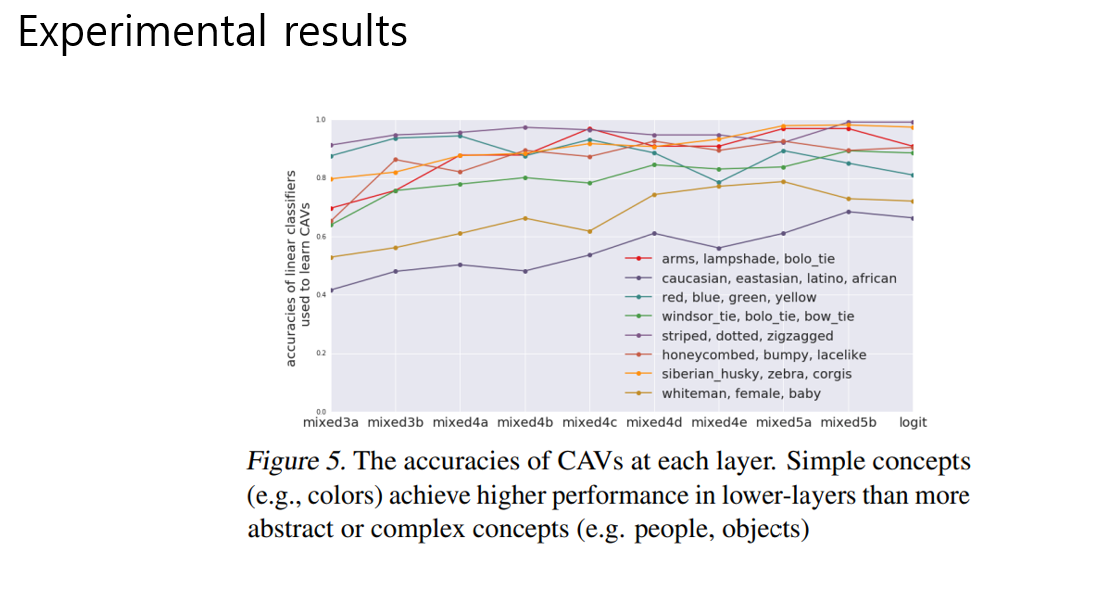
각 컨셉은 어디 layer에서 더 잘 배워질까 . CAV에 대한 linear classifier를 만들떄 어디 layer에서 뽑아야 더 정확도가 높을까를 보기위한 실험이다.
high level feature는 뒤쪽 레이어에서 높았고 색깔, 패턴, 같은 low level feature 는 앞이 더 높음
(사실 그리 차이나보이지않음)

TCAV의 목적은 Human이 적절한 Domain Concept를 골랐을 때 해당 이미지가 딥러닝모델에 도움이 됐는지(스코어가 높은지) 확인할 수 있다는 것. 결론은 ground-truth(캡션이나 컨셉 이미지 같은)를 잘 구축해놓고 실험을 했을 때 인공지능에게도 도움이 되고, 인간이 이해하는데에도 도움이 된다. 그걸위해 TCAV는 좋은 보조장치임을 증명했음
https://arxiv.org/pdf/1711.11279.pdf